
MySQL笔记-数据库性能优化
SQL性能分析
查看SQL执行信息(Profile)
Profile简介
在MySQL中,”Profile”是一个用于性能分析和调优的特殊功能。Profile允许捕获并分析查询语句的执行情况,以便确定潜在的性能问题和瓶颈。Profile通常提供以下信息:
- 查询执行时间:SQL查询的总执行时间以及每个操作阶段的执行时间。
- 资源使用情况:CPU、内存和磁盘等资源在执行过程中的使用情况。
- 操作顺序:SQL查询中每个操作的执行顺序。
开启Profile
Profile是MySQL数据库提供的一种用于查看SQL查询执行信息的功能,默认默认是关闭的,可以执行以下命令来开启Profile功能:
1 | # 查看当前的 MySQL 版本是否支持 profile |
使用Profile
运行需要分析的SQL查询,然后可以通过Profile查看执行过程和资源消耗统计信息
1 | # 运行需要分析的SQL查询 |
查看状态变量(Status)
状态变量简介
状态变量(Status Variables)是用于描述和监控数据库服务器运行状态的参数。这些状态变量包括各种指标和操作次数,如连接数、线程数、查询次数、I/O 操作和内存使用等。通过查看状态变量,可以了解数据库服务器的实时性能和资源占用情况。根据会话域的不同,可以分为会话服务器状态变量和全局服务器状态变量,可以使用下面的命令查看:
1 | # 查看当前会话服务器状态变量,仅适用于当前会话,并在会话结束后被重置。 |
这两个命令共享同一套变量名称,但显示的是不同的作用域和范围。具体解释如下:
Com_xxx:这些变量记录了执行各种 SQL 语句的次数,如Com_insert表示执行了多少次插入语句。Connections:当前已经建立的连接数量。Threads_connected:当前正在使用的连接数量。Threads_running:正在运行的线程数量。Innodb_xxx:这些变量提供了 InnoDB 存储引擎的相关信息,如Innodb_buffer_pool_reads表示从磁盘读取的页数。Created_tmp_xxx:这些变量记录了创建临时表和文件的次数和数量。Handler_xxx:这些变量提供了关于查询处理器操作的信息,如Handler_read_first表示读取表的第一行的次数。Bytes_xxx:这些变量记录了传输的字节数量,如Bytes_received表示已接收的字节数。Uptime:MySQL 服务器运行的时间。
Com前缀
在MySQL中,Com 前缀的状态变量记录了执行各种 SQL 语句的次数。可以通过执行以下命令来查看:
1 | # 查看当前会话的状态计数器 |
下面是几个常见的以 Com 前缀开头的状态变量:
Com_select:表示执行 SELECT 查询语句的次数。Com_insert:表示执行 INSERT 插入语句的次数。Com_update:表示执行 UPDATE 更新语句的次数。Com_delete:表示执行 DELETE 删除语句的次数。Com_commit:表示执行 COMMIT 事务提交的次数。Com_rollback:表示执行 ROLLBACK 事务回滚的次数。Com_create_table:表示执行 CREATE TABLE 创建表的次数。Com_alter_table:表示执行 ALTER TABLE 修改表结构的次数。Com_drop_table:表示执行 DROP TABLE 删除表的次数。Com_show_tables:表示执行 SHOW TABLES 显示表列表的次数。
根据Com 前缀的状态变量可以确定当前数据库到底是以查询为主,还是以增删改为主
- 数据库以查询为主:可以考虑对查询频繁的表进行索引优化;如果数据库以增删改为主,
- 数据库以增删改为主:不进行索引优化,重点关注事务处理、缓存策略、数据分片等方面的优化。
1 | # 显示当前会话中执行了多少次删除操作(Com_delete) |
查看SQL慢查询日志(localhost-slow.log)
慢查询简介
慢查询日志记录了所有执行时间超过指定参数的所有 SQL语句的日志,通过慢查询日志,就可以定位出执行效率比较低的SQL,从而有针对性的进行优化。默认情况下,慢查询日志在数据库中是关闭状态,可以通过下面的命令查看是否开启慢查询日志
1 | show variables like "slow_%" |
- slow_query_log:若值为 ON,则表示慢查询日志已开启;若值为 OFF,则表示慢查询日志已关闭。
- slow_launch_time:慢查询阈值(单位为秒),超过该阈值的 SQL 语句将被记录在慢查询日志中。
- slow_query_log_file:表示慢查询日志的文件路径,默认文件名称为
主机名-slow.log。
开启慢查询日志
修改在MySQL的my.cnf配置文件,开启慢查询日志(修改后需要重启服务)
1 | # 开启MySQL慢日志查询开关 |
慢查询日志的存储位置
默认慢查询日志的存储位置如下
- Windows操作系统默认存储位置:C:\ProgramData\MySQL\MySQL Server 8.0\data\主机名-slow.log
- Linux操作系统默认存储位置: /var/log/mysql/mysql-slow.log
1 | # 查看慢查询日志的存储位置 |
查看SQL执行计划(Explain)
执行计划简介
每条SQL语句执行之前,都会先计算该SQL语句需要调用的相关资源,再决定该SQL语句是否要最终执行,该行为被称为“执行计划”。执行计划主要用于分析 SQL 语句的执行情况,包括索引的使用情况、表的访问方式、连接操作的顺序等,并不实际执行查询。
执行计划使用
MySQL 提供了一个内置的查询执行计划分析工具,称为 EXPLAIN。使用EXPLAIN查看 SQL 语句的执行计划,语法如下
1 | explain SQL语句; |
执行计划字段信息
MySQL执行计划 EXPLAIN 命令获取到的字段信息如下
| 参数 | 简介 |
|---|---|
| id | 查询块的唯一标识符。对于复杂的查询语句,查询块会按照特定的顺序被编号,id 值越小表示该查询块的执行优先级越高。 |
| select_type | 查询的类型,常见取值有以下几种:SIMPLE:简单查询,不包含子查询或 UNION 查询PRIMARY:主查询,最外层的查询SUBQUERY:子查询,嵌套在其他查询中DERIVED:派生表中的 SELECT 查询UNION:UNION操作查询UNION RESULT:UNION 查询结果 |
| table | 当前查询涉及的表名称 |
| partitions | 当前查询涉及的分区名称 |
| type | 查询的连接类型,常见取值有以下几种:system:表示结果只有一行const:使用常量值进行匹配,通常是在没有索引的情况下eq_ref:唯一索引等值匹配ref:非唯一索引等值匹配fulltext: 全文检索range:使用索引范围匹配index:扫描全索引all:全表扫描ref_or_null:类似于 ref,但还包括对 NULL 值的引用index_merge: 使用了多个索引进行合并扫描unique_subquery: 在子查询中使用了唯一索引查找结果index_subquery: 在子查询中使用了非唯一索引查找结果 |
| possible_keys | 可能会用到的索引,索引越多,说明有更多的选择余地。 |
| key | 实际上使用的索引,如果为NULL,则没有使用索引。 |
| key_len | 使用的索引长度(以字节数表示), 该值是最大可能长度,并非实际使用长度,在不损失精确性的前提下, 长度越短越好 |
| ref | 连接使用的列或常量 |
| rows | MySQL 认为必须检查的行数。这个值是优化器根据统计信息和查询条件的估计值,并不总是准确的。 |
| filtered | 表示返回结果的行数占需读取行数的百分比, 值越大越好。 |
| Extra | 额外信息,用于进一步解释查询执行的细节和附加操作,常见取值有以下几种:Using index:表示查询使用了覆盖索引(Covering Index)查询时可以直接从索引中获取所需的数据,不必回到表中检索数据Using index condition:表示查询时利用索引中的部分列进行了过滤,需要回到表中检索符合条件的所有行Using index for group-by:表示查询使用了索引来进行 GROUP BY 操作Using index for order by:表示查询使用了索引来进行 ORDER BY 操作Using where:表示查询需要在结果集中使用 WHERE 子句进行过滤Using join buffer:表示查询使用了连接缓冲区(Join Buffer)Using temporary:表示查询需要使用临时表(Temporary Table)来处理结果集Using filesort:表示查询需要对结果集进行排序Using disk sort:表示查询需要使用外部磁盘进行排序Using union:表示查询使用了 UNION 操作Using intersect:在多个全文索引之间进行交集计算Using sort_union:在联合子查询中使用了排序和并集优化器。 |
索引(index)
索引是什么
索引是一种数据结构,用于加速数据库中的数据查询。类似于书籍的目录,可以帮助我们快速地找到需要的内容。在数据库中,索引通常是一张包含键值和指向实际数据行的指针的表格
索引的优缺点
索引的优点
- 提高查询效率:索引可以提高查询效率,因为它可以使MySQL直接跳过不需要检索的行,从而减少了IO操作和CPU消耗。
- 确保数据完整性:索引可以确保数据的完整性,因为可以强制执行唯一性约束、非空值约束等。
- 加速排序:当使用ORDER BY操作时,MySQL可以利用索引的排序特性来进行快速排序,从而加快查询速度
- 加速分组:对分组操作的字段建立索引,可直接利用索引的排序特性来执行分组操作,减少了排序和分组的时间和资源消耗
索引的缺点
- 需要持续维护:索引需要随着数据的变更而维护,这会增加数据库的负担
- 占用磁盘空间:索引也是一个文件,需要额外的空间来存储,这可能会占用大量的磁盘空间
- 降低更新性能:降低更新的速度,每次插入、更新或删除操作都需要更新索引,这可能会使写入操作的性能下降
- 不适合小表:对于非常小的表格来说,使用索引可能会降低查询性能,因为索引本身需要消耗资源
- 可能导致锁冲突:当多个事务同时访问同一个表时,索引可能会导致锁冲突,从而影响并发性能
索引的分类
根据索引的字段特性分类
| 索引 | 简介 |
|---|---|
| 常规索引 | 快速定位特定数据 |
| 主键索引 | 针对于表中主键创建的索引 |
| 唯一索引 | 索引列的值必须唯一,但允许有空值。 |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比 较索引中的值 |
| 空间索引 | 空间索引 是对 空间数据类型 的字段 建立的索引 |
| 前缀索引 | 对索引列的前缀进行索引,可以节省索引存储空间 |
根据索引的字段个数分类
| 索引 | 简介 |
|---|---|
| 单值索引 | 即一个索引只包含单个列,一个表可以有多个单列索引 |
| 复合索引 | 即一个索引包含多个列 |
根据索引的存储形式分类
| 索引 | 简介 |
|---|---|
| 聚集(簇)索引 | 聚集(簇)索引是基于表中的主键或唯一约束创建的一种索引,主要作用是对表进行物理排序,使得相邻的行存储在一起,每个表只能有一个,并且该索引决定了数据在物理上的存储顺序 |
| 非聚集(簇)索引(也称为辅助索引或二级索引) | 非聚集(簇)索引,也称为辅助索引或二级索引,是基于表中的普通列创建的一种索引,用于加速对这些列的查询和排序操作,可以有多个 |
索引的语法
建表时指定索引
1 | create table [if not exists]表名称( |
注意事项:
- 一个表只能创建一个主键索引,但可以创建多个唯一索引、普通索引、全文索引
- 空间索引只能添加在非空的空间类型字段上
- length 为可选参数,表示索引的长度,只有字符串类型的字段才能指定索引长度
- MySQL5.7索引默认asc升序排序,MySQL8.0支持desc降序索引,空间索引和全文索引不支持指定排序顺序
使用案例:
1 | create table if not exists users( |
建表后指定索引
1 | # 为指定表字段创建主键索引,确保表中某列(或多列)数据的唯一性和非空性 |
查看索引
1 | # 方式一 |
添加索引
1 | # 添加主键索引,确保表中某列(或多列)数据的唯一性和非空性 |
删除索引
1 | # 方式一 |
索引的禁用与开启
1 | # 禁用索引,只会禁用非唯一索引,唯一索引和主键索引不会被禁用 |
索引的数据结构
MySQL的索引是在存储引擎层实现的,平常所说的索引,如果没有特别指明,都是指B+树结构组织的索引
| 索引结构 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+Tree | √(MySQL5.6+) | √(MySQL4.0+) | √(ALL) |
| Hash | ×(不支持) | ×(不支持) | ×(ALL) |
| R-Tree | √(MySQL5.6+) | ×(NO) | ×(不支持) |
| Full-text | √(MySQL5.6+) | √(MySQL4.1+) | ×(不支持) |
| 索引结构 | 简介 |
|---|---|
| Hash(哈希索引) | 使用哈希表进行存储的索引类型,Key 存储索引列,Value 存储行记录或行磁盘地址 Hash 只支持等值查询(=,IN,<=>) Hash 不支持任何范围查询( between , > , < , … ),因为每个键之间没有任何的联系 |
| B+Tree(B+树索引) | 最常见的索引类型,大部分引擎都支持 B+ 树索引,用于存储有序数据,适合范围查询、排序和分组等操作 |
| R-tree(空间索引) | 空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少 |
| Full-text(全文索引) | 全文索引,是一种通过建立倒排索引,快速匹配文档的方式,类似于 Lucene、Solr、ES |
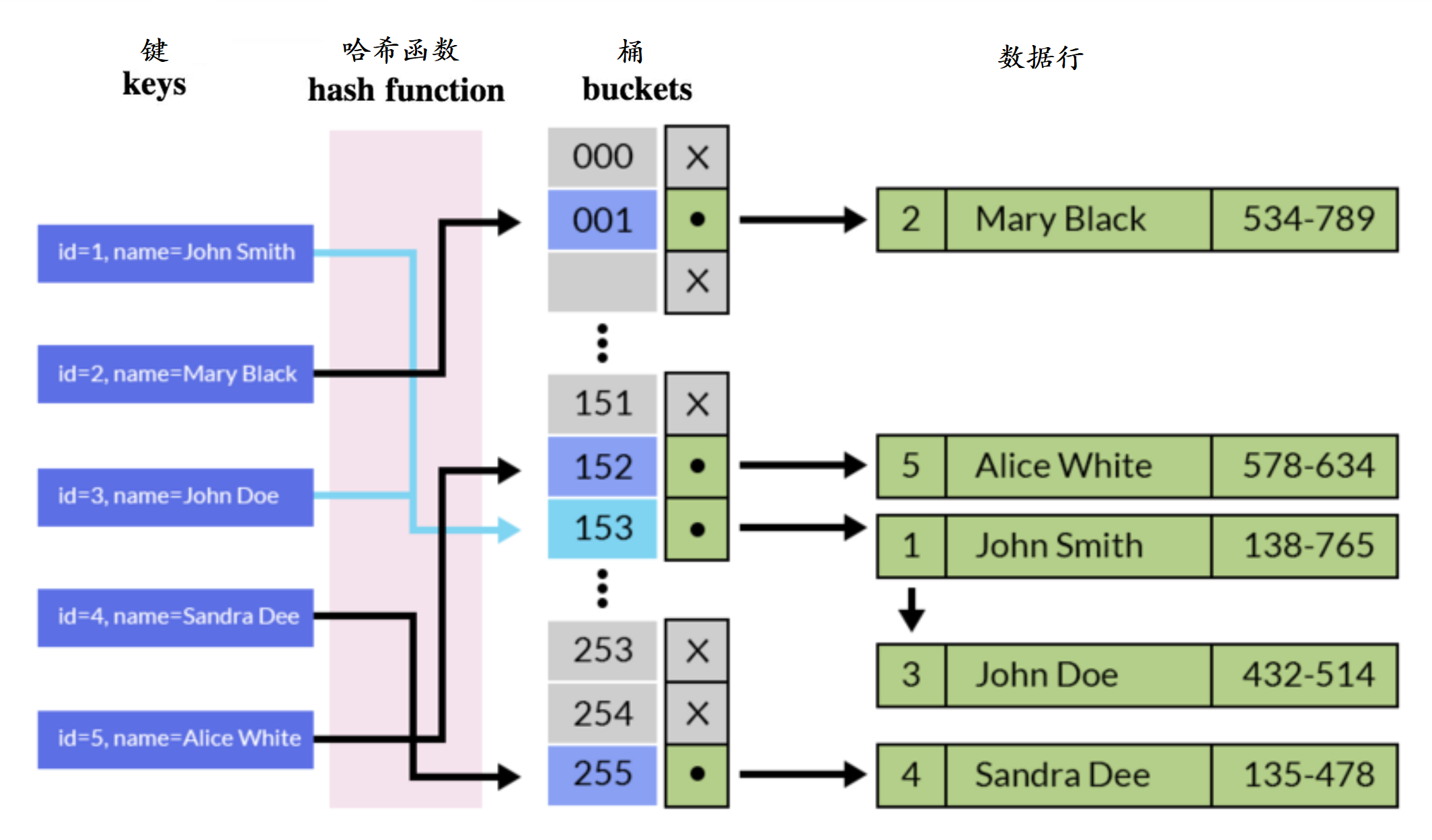
哈希索引(Hash)
哈希表(Hash table),存储键值对(Key Value)数据的一种数据结构
哈希表可以看作是由数组和链表组成的数据结构,其中数组被称为哈希桶(bucket),每个桶中存储一个链表
哈希表通过哈希函数,将键映射到数组的某个位置上,当需要存储数据时,先根据哈希函数,计算出数据对应的哈希桶的位置,然后将数据插入到该位置对应的链表中
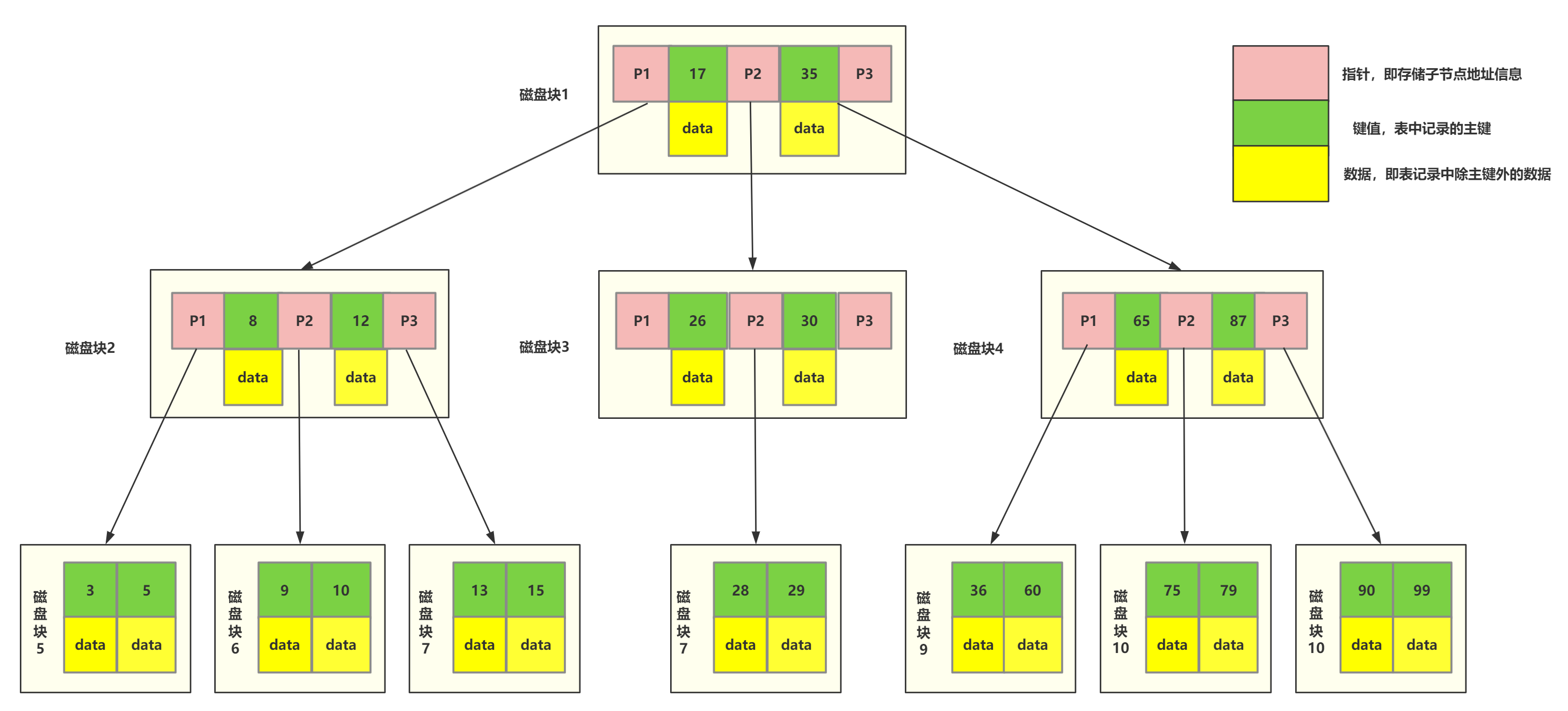
B 树(B Tree)
B树是一种自平衡多叉搜索树,所有节点既存放键(key)也存放数据(data)
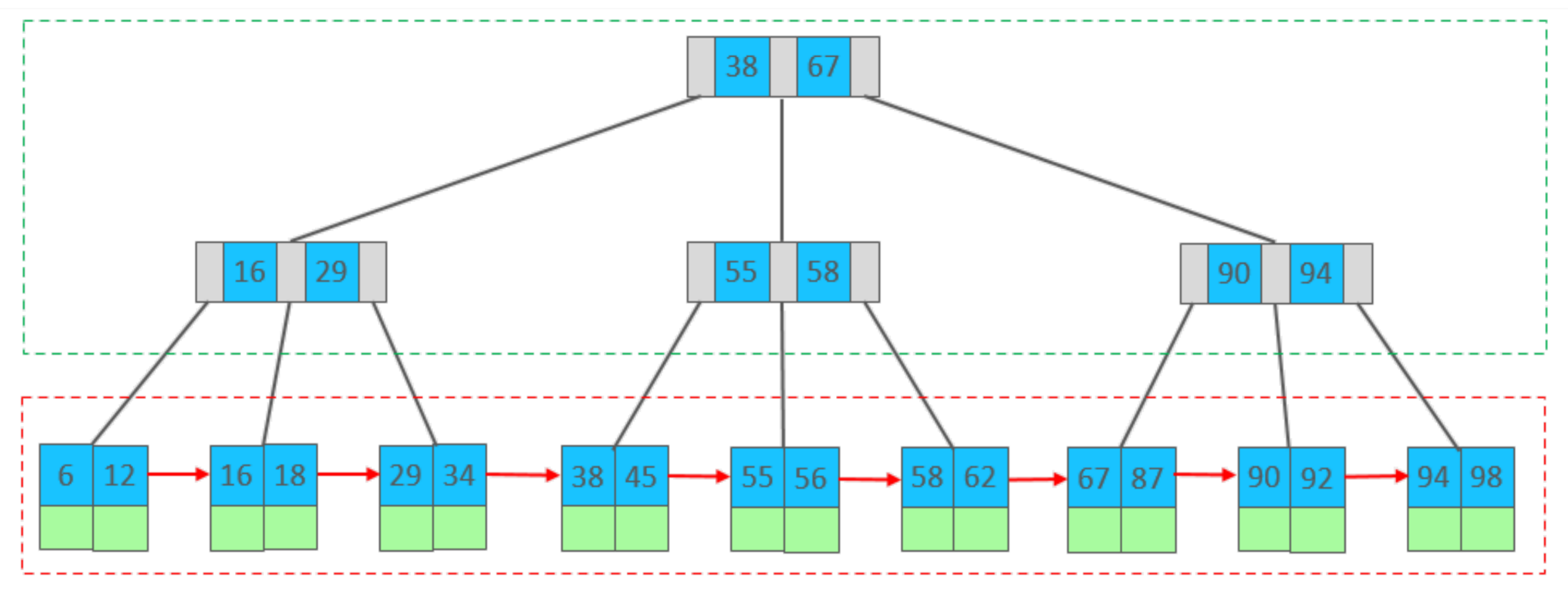
B + 树(B + Tree)
B + Tree是B 树的变种,在 B 树基础上为叶子节点增加了单向指针,形成有序链表,并且只有叶子节点存放键(key)和数据(data),非叶子节点只存放键(key)
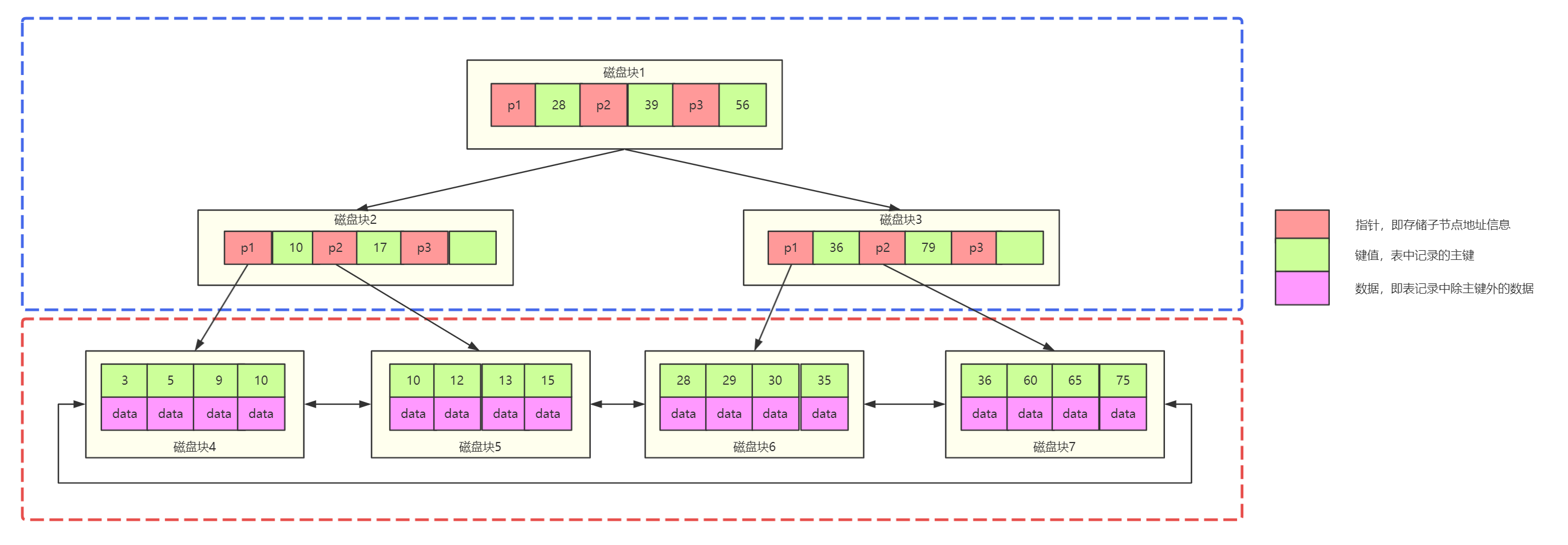
MySQL中的 B + 树(B + Tree)
MySQL索引数据结构对经典的B+Tree进行了优化,将B+ 树中叶子节点之间的单向指针改为双向指针,形成双向链表,可以从两个方向依次遍历叶子节点,可以更快速地定位范围内的数据块,提高查询效率
InnoDB中一颗B+树可以存放多少行数据?
在InnoDB中,一颗B+树可以存放多少行数据是由多个因素决定的,包括页大小,数据行大小以及树的层级等,一个三层的B+树大约可存2200万条数据。
- 页大小:在InnoDB的B+树结构中,数据是以页(Page)为单位进行存储和管理的,每个页的默认大小为16KB(16 * 1024字节)。
- 数据行大小:每行数据的大小取决于所存储的列以及其数据类型,不同的列会占用不同的空间。假设一条数据占 1 kb 的空间,那么一个页可以存放 16 条这样的数据。
每个B+树节点都对应一个页(page),这些页通常被称为数据页或索引页,它们存储了数据库中的索引和数据。
- B+树叶子节点:每个叶子节点对应一个数据页,用来存放实际的数据行。假设一条数据占 1 kb 的空间,那么一个叶子节点可以存放 16 条这样的数据。
- B+树非叶子节点:每个非叶子节点都对应一个索引页,用来存放索引信息,由指向下一层地址的指针和主键值组成。指针大小在InnoDB源码中设置为6字节,如果主键是bigint类型,会占8个字节。
根据上述信息,可以计算出一个非叶子节点(索引页)中可以存储的索引信息(主键+指针)数量:(16 * 1024) / (6 + 8) ≈ 1170,就是说一个非叶子节点(索引页)中可以存放大约1170个指向下一层地址的指针,下一层大约有1170个叶子节点(数据页)。
综合上述信息,可以得出不同B+树层级的数据存储情况:
- 如果B+树有1层,那么根节点就是叶子节点(数据页),最多能存放
16条记录,大约占用16 KB空间; - 如果B+树有2层,那么第一层是非叶子节点(索引页),指向下一层地址的指针有
1170个,第二层都是叶子节点(数据页)会有1170个,最多能存放1170 × 16 = 18720条记录,大约占用18.72 MB空间; - 如果B+树有3层,那么第二层是非叶子节点(索引页),指向下一层地址的指针有
1170 x 1170个,第三层都是叶子节点(数据页)会有1170 x 1170个,最多能存放1170 x 1170 x 16 = 21902400条记录,大约占用21.9 GB空间;
聚簇索引与非聚簇索引
聚簇索引
(1)在InnoDB中,每张表都有一个特殊的索引叫做聚簇索引(也叫聚集索引),它是按照主键顺序存储的B+树,叶子节点同时存储了主键值和整行数据,整张表的数据都存储在聚簇索引中
(2)一个表只能有一个聚簇索引,主键一定是聚簇索引
(3)通过主键可以直接在聚簇索引找到对应的行数据
(4)聚簇索引的建立原则
- 如果一个主键被定义了,那么这个主键就是作为聚簇索引
- 如果没有主键被定义,那么该表的第一个唯一非空索引被作为聚簇索引
- 如果没有主键也没有合适的唯一索引,那么InnoDB内部会生成一个隐藏的主键作为聚簇索引
非聚簇索引
(1)除了聚簇索引外的其它索引都叫非聚簇索引(也称为非聚集索引或辅助索引或二级索引),与聚簇索引的区别是叶子节点中只存了索引列和主键值,索引和数据是分开的
(2)一个表可以有多个非聚簇索引,唯一索引、单列索引、复合索引都属于二次索引,只是从逻辑角度进行的分类
(3)通过二级索引需要先找到主键值,再根据主键值到聚簇索引找到对应的行,也就是平常说的要进行一次回表操作
聚簇索引与非聚簇索引区别
| 区别 | 聚集(簇)索引 | 非聚集(簇)索引(也称为辅助索引或二级索引) |
|---|---|---|
| 索引数量 | 每张表只能有一个 | 每张表可以有多个 |
| 叶子节点 | 叶子节点存储的是整行数据 | 叶子节点存储的是键值和指向对应数据行的物理地址(也称为指针) |
| 非叶子节点 | 非叶子节点存储的是键值和指向下一级节点的地址 | 非叶子结点存储的是键值和指向下一级节点的指针 |
| 返回数据的方式 | 找到一个符合条件的记录时可以直接返回整行数据 | 先通过索引找到对应的记录地址 再根据地址访问数据页 最终获取整行数据 |
| 存储方式 | 数据和索引结构存储在一起 | 数据和索引结构分开存储 |
| 存储顺序 | 以聚集索引的索引树作为表数据的存储顺序 | 无固定存储顺序 |
| 性能影响 | 更新、插入操作性能好; | 查询操作性能好,更新、插入操作性能差; |
覆盖索引和回表查询
已知信息
已知下表tb_user,id是主键,是一个聚集索引。 name字段建立了普通索引,是一个二级索引(辅助索引)
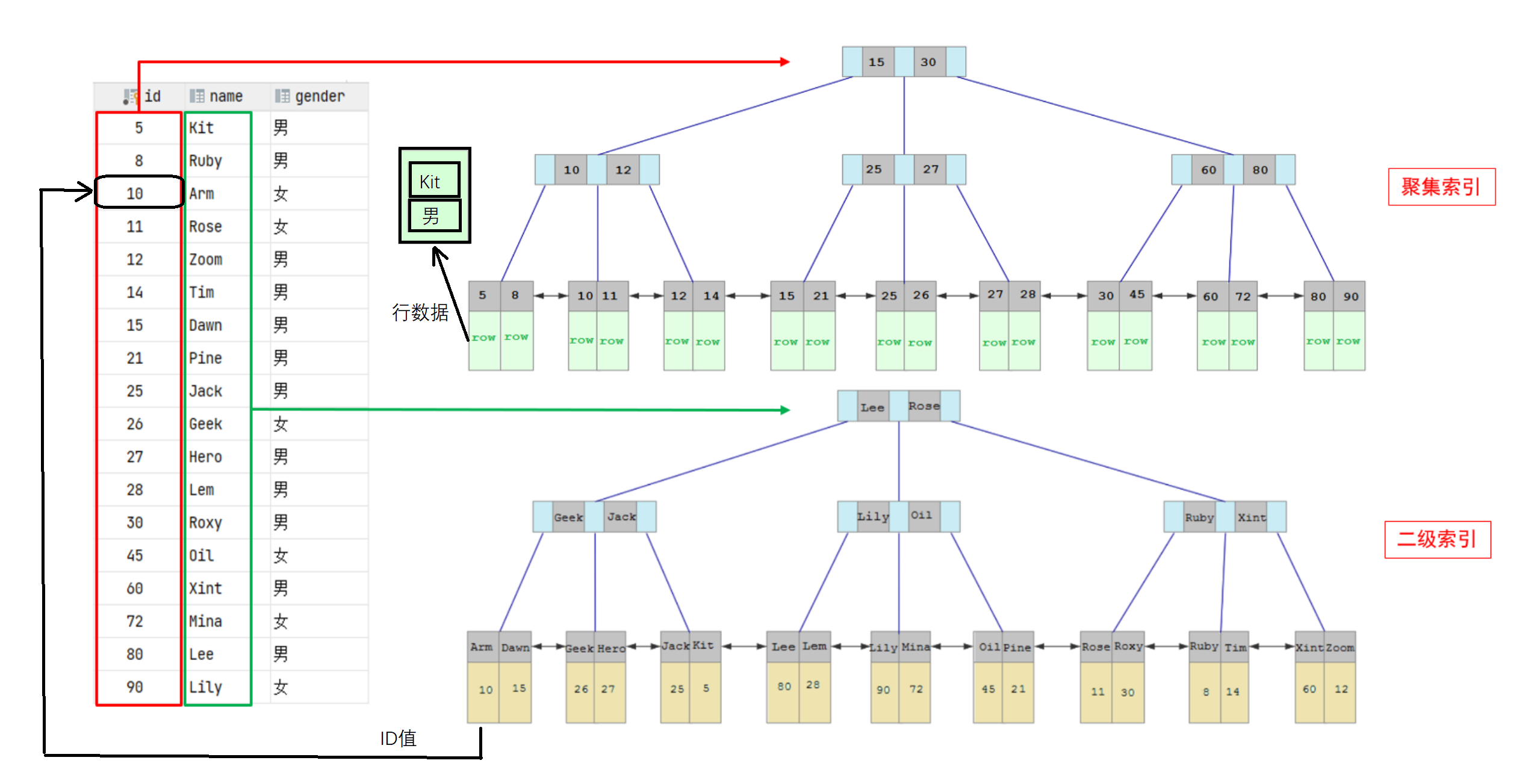
执行如下SQL根据id查询一条数据,会直接走聚集索引查询并返回数据,只会涉及一次索引扫描,性能高。因为id是主键,主键默认会建立聚集索引,并且聚集索引叶子节点含有完整数据,可以直接利用该索引定位到指定的数据行,并且直接返回相应的数据
1 | select * from tb_user where id = 5; |
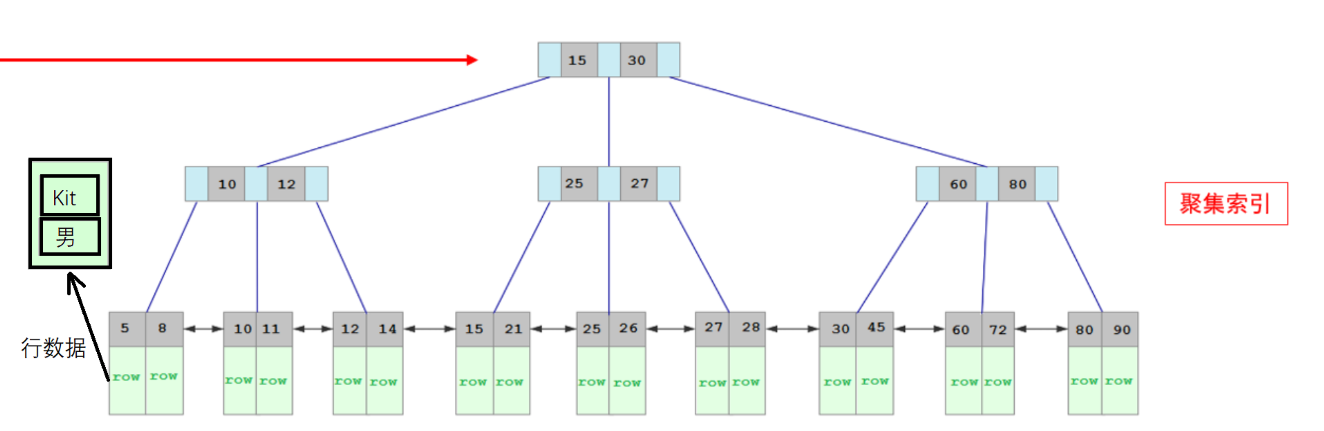
覆盖索引
执行如下SQL会根据id查询id和name,因为id和name两个值都是可以直接获取到的,属于覆盖索引,会直接走二级索引并返回数据,性能高
1 | select id,name from tb_user where name = 'Arm'; |
<img src=”MySQL-4-数据库优化\覆盖索引.png” style=”zoom:50%;” /
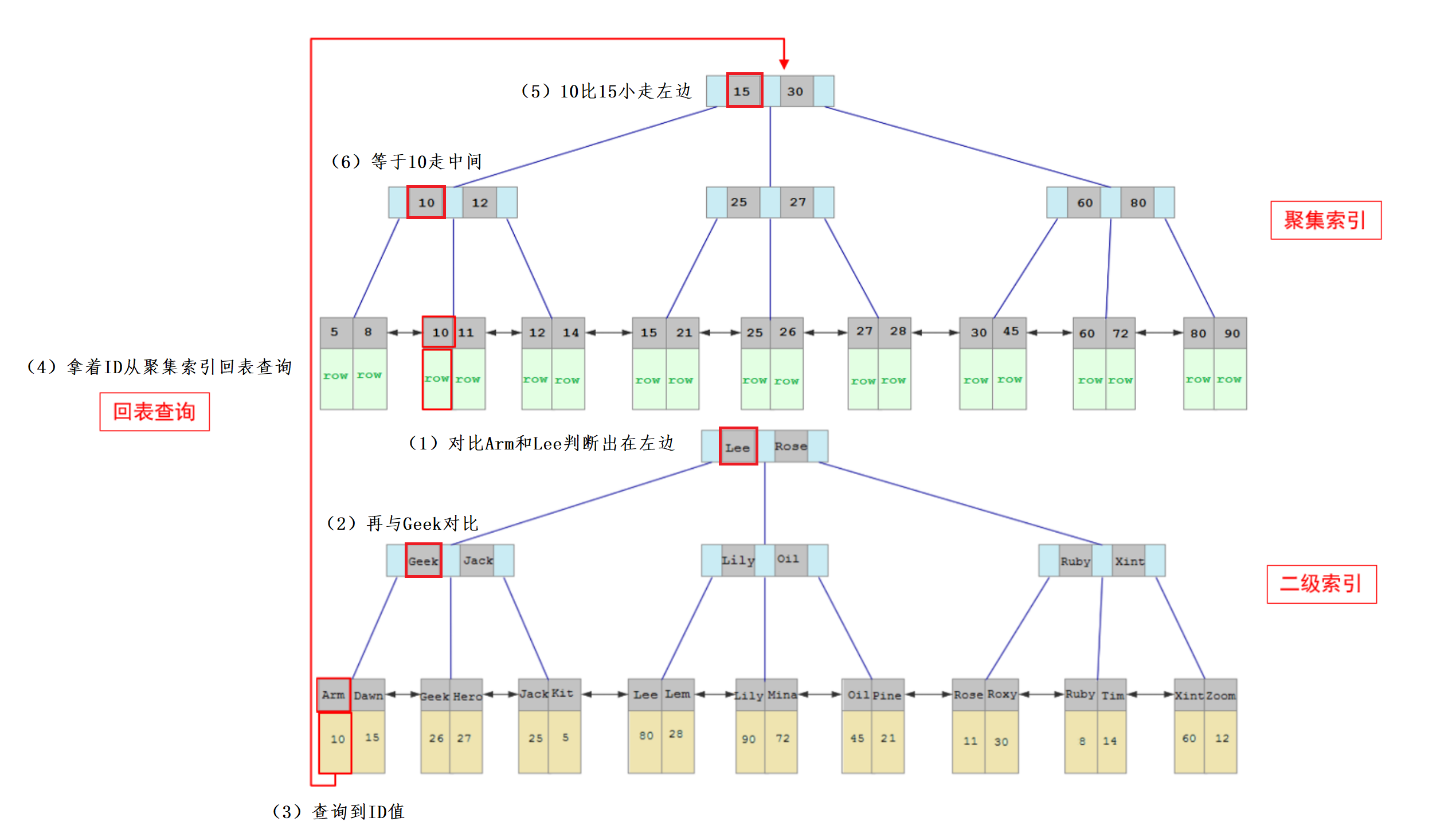
回表查询
执行如下SQL时,由于是根据name字段进行查询,所以不能直接使用聚集索引进行查询,而是先根据name=’Arm’到name字段的二级索引中进行匹配查找主键ID值10,根据主键ID值10,到聚集索引中查找10对应的记录,最终找到10对应的row行数据返回,性能相对较差一点
1 | select * from tb_user where name = 'Arm'; |
索引的失效情况
测试表和测试数据
1 | CREATE TABLE `users` ( |
对索引列使用不等于匹配
当查询条件中使用!=或<>符号来匹配索引列时,索引将无法使用。这是因为索引通常按照值的顺序进行存储和排序,不等于操作需要对所有可能的值进行比较,无法有效利用索引的有序性进行快速查找。使用等于符号=来匹配索引列时,能使用索引。
1 | # 为name字段创建索引 |
对索引列使用IS NOT NULL
当查询条件使用IS NOT NULL来匹配索引列时,索引将失效。原因是索引只包含有值的行,而IS NOT NULL操作需要检查所有行,因此无法使用索引加速查询。使用IS NULL来匹配索引列时,能使用索引。
1 | # 为gender字段创建索引 |
对索引列进行模糊查询like以%开头
当使用LIKE语句进行模糊查询时,如果通配符%出现在查询模式的起始位置,索引也会失效。因为索引是按照值的顺序存储的,无法利用索引的有序性,必须逐行扫描表中的数据。可以通过使用覆盖索引,只查询索引列来避免索引失效。
1 | # 为email字段创建索引 |
对索引列进行运算操作
当查询条件对索引列进行运算操作时,索引将失效。运算操作会改变列的值,使得索引无法提供正确的匹配。
1 | # 为age字段创建索引 |
对索引列进行函数操作
当查询条件对索引列进行函数操作时,索引将失效。函数操作会生成新的值,无法在索引中进行匹配。
1 | # 为create_time字段创建索引 |
使用运算符OR前后存在非索引的列
如果查询条件中使用了 OR,那么除非每个 OR 条件都能使用索引,否则索引可能会失效。要保证每个OR条件都能使用索引才能保证索引有效。因为OR操作需要对所有的条件进行计算,一旦出现非索引列,就无法使用索引加速查询。
1 | # 为name字段创建索引 |
复合索引违反最左前缀法则
如果不使用该复合索引的最左边的索引列,则该复合索引会失效,如果跳过复合索引中的某一索引列,则这一索引列后面的索引会失效。
1 | # 创建一个复合索引 |
数据库优化
查询优化
避免使用SELECT * 查询
使用 SELECT * 会查询表中的所有列,包括不需要的列,这会增加数据传输量和内存消耗。明确指定需要查询的列可以减少不必要的资源消耗。
1 | # 不推荐 |
避免使用不必要的DISTINCT去重
使用 SELECT DISTINCT 去重会增加查询的开销,因为它需要在结果集上执行排序和比较操作。如果不必要,尽量避免使用 DISTINCT,而是通过其他方式进行去重操作。
1 | # 不推荐 |
避免不必要的ORDER BY排序
如果只关心查询结果的数据,而不需要按特定顺序排列,那么可以删除 ORDER BY 子句,提高查询性能。
1 | # 不推荐 |
避免使用多个JOIN联表查询
多个 JOIN 联表查询会引入更多的关联和数据扫描成本。在实际应用中,可以考虑拆分查询进行优化,以减少联接操作的复杂性。
1 | # 不推荐 |
避免使用子查询
子查询可能会执行多次,每次执行都会引入额外的开销。通过使用 JOIN 或临时表进行联接,可以将子查询转换为更高效的连接操作,从而提高查询性能。
1 | # 不推荐 |
使用INNER JOIN代替LEFT JOIN或RIGHT JOIN
INNER JOIN 只返回匹配的行,而 LEFT JOIN 或 RIGHT JOIN 还会返回左表或右表中未匹配的行。如果不需要这些额外的数据,尽量使用 INNER JOIN,可以减少不必要的数据扫描和连接操作。
1 | # 不推荐 |
使用WHERE替换HAVING子句
HAVING 子句用于对分组后的结果进行过滤,而 WHERE 子句用于对原始数据进行过滤。将过滤条件放在 WHERE 子句中可以减少分组的数据量,提高查询效率。
1 | # 不推荐 |
使用UNION ALL代替UNION
UNION 操作会对结果集进行去重操作,而 UNION ALL 不会。如果不需要去重,可以使用 UNION ALL 替代 UNION,从而减少排序和比较的开销。
1 | # 不推荐 |
使用LIMIT子句限制查询结果
LIMIT 子句允许你限制查询结果的数量。当只需要获取部分查询结果时,通过使用 LIMIT 可以减少数据传输和处理的开销。
1 | # 不推荐 |
使用NOT EXISTS替代NOT IN
NOT IN子句和 NOT EXISTS 子句都可以用于子查询,判断某个值是否不存在。但是 NOT EXISTS 更高效,因为它只需要判断是否不存在结果,而不需要检索具体的值。
1 | # 不推荐 |
使用EXISTS替代IN
IN 子句和 EXISTS 子句都可以用于子查询,判断某个值是否存在。但是 EXISTS 更高效,因为它只需要判断是否存在结果,而不需要检索具体的值。
1 | # 不推荐 |
索引优化
通过合理选择字段添加索引、使用联合索引、避免过多索引以及定期维护和优化索引,可以最大程度地提高数据库的查询性能,并确保索引的有效性和一致性。
- 频繁访问的字段适合添加索引:通过为频繁使用的字段添加索引,可以加快查询操作的速度。这样可以减少数据库的扫描次数,提高查询效率。
- 使用联合索引来覆盖查询:在某些情况下,单个索引无法满足复杂的查询需求。使用联合索引可以在一个索引中包含多个列,以便更好地支持复杂的查询操作。联合索引能够通过覆盖查询(Covering Index)的方式,直接从索引中获取所需数据,而不必再去查询表的行数据,从而提高查询性能。
- 避免过多的索引:过多的索引会使数据库写操作的性能下降,并且会占用更多的存储空间。每个索引都需要维护和更新,因此过多的索引会增加数据库维护的成本。因此,在创建索引时,需要评估每个索引的必要性,并避免创建不必要的索引。
- 维护索引并避免索引失效:随着数据的插入、更新和删除,索引的数据也会发生变化。为了保证索引的有效性和性能,需要定期维护索引。维护索引可以包括重建索引、重新组织索引等操作。此外,还需要避免使用不符合索引定义的查询,以免触发索引失效。
避免对索引列使用不等于匹配
当查询条件中使用!=或<>符号来匹配索引列时,索引将无法使用。这是因为索引通常按照值的顺序进行存储和排序,不等于操作需要对所有可能的值进行比较,无法有效利用索引的有序性进行快速查找。使用等于符号=来匹配索引列时,能使用索引。
1 | # 为name字段创建索引 |
避免对索引列使用IS NOT NULL
当查询条件使用IS NOT NULL来匹配索引列时,索引将失效。原因是索引只包含有值的行,而IS NOT NULL操作需要检查所有行,因此无法使用索引加速查询。使用IS NULL来匹配索引列时,能使用索引。
1 | # 为gender字段创建索引 |
避免对索引列进行模糊查询like以%开头
当使用LIKE语句进行模糊查询时,如果通配符%出现在查询模式的起始位置,索引也会失效。因为索引是按照值的顺序存储的,无法利用索引的有序性,必须逐行扫描表中的数据。可以通过使用覆盖索引,只查询索引列来避免索引失效。
1 | # 为email字段创建索引 |
避免对索引列进行运算操作
当查询条件对索引列进行运算操作时,索引将失效。运算操作会改变列的值,使得索引无法提供正确的匹配。
1 | # 为age字段创建索引 |
避免对索引列进行函数操作
当查询条件对索引列进行函数操作时,索引将失效。函数操作会生成新的值,无法在索引中进行匹配。
1 | # 为create_time字段创建索引 |
避免使用运算符OR前后存在非索引的列
如果查询条件中使用了 OR,那么除非每个 OR 条件都能使用索引,否则索引可能会失效。要保证每个OR条件都能使用索引才能保证索引有效。因为OR操作需要对所有的条件进行计算,一旦出现非索引列,就无法使用索引加速查询。
1 | # 为name字段创建索引 |
避免复合索引违反最左前缀法则
如果不使用该复合索引的最左边的索引列,则该复合索引会失效,如果跳过复合索引中的某一索引列,则这一索引列后面的索引会失效。
1 | # 创建一个复合索引 |
插入优化
批量插入
假如需要插入多条数据,可以使用多条 INSERT 语句一次性插入多条数据,减少与数据库的交互次数,提高效率
1 | # 不推荐 |
使用事务
假如需要插入多条数据,可以将多个插入操作放在一个事务中,可以控制数据的一致性,同时也可以提高插入效率
1 | # 不推荐 |
禁用索引
如果需要插入大量数据,而且这些数据并不需要立即查询,可以在插入前暂时禁用索引,插入完毕后再重新启用索引,可以提高插入效率
1 | alter table 表名 disable keys; # 禁用索引 |
使用LOAD DATA INFILE导入
如果数据源是外部文件,可以使用LOAD DATA INFILE命令可以高效地将外部文件中的数据导入到表中,这种方式比逐行插入更高效,但文件格式需要符合MySQL的要求。
1 | LOAD DATA INFILE '文件路径' INTO TABLE 表名 |
表设计优化
使用合适的存储引擎
MySQL支持多种存储引擎,如InnoDB、MyISAM等。根据场景选择合适的存储引擎可以提高性能。
- InnoDB是MySQL的默认存储引擎,它支持事务处理和行级锁定,并具有很好的并发性能。对于大多数情况,使用InnoDB存储引擎是一个明智的选择。
- MyISAM存储引擎适用于更多的读取操作,但不支持事务处理和行级锁定。
单表不要包含过多字段
当表的列过多时,会增加查询和写入的复杂度,并且会占用更多的磁盘空间。可以将相关的字段组织在一起,将不常用的字段拆分成其他表,以减少冗余和提高查询效率。
禁止存储较大二进制数据
存储较大的二进制数据(如图片、音频等)可能会导致数据库表的膨胀,影响查询和更新的性能。如果需要存储大型文件或二进制数据,建议将其存储在文件系统中,并在数据库中存储相应的路径或引用。
正确选择合适的数据类型
选择合适的数据类型可以减少存储空间的占用并提高查询效率
- 使用合适大小的整数类型,如TINYINT、SMALLINT等,避免使用较大的整数类型,以节省存储空间。
- 使用VARCHAR而不是CHAR,VARCHAR只占用实际使用的存储空间,而CHAR占用固定的存储空间。
- 对于小文本字段,使用TEXT或MEDIUMTEXT类型,而不是VARCHAR。
- 避免使用ENUM类型,因为它在某些情况下可能会导致数据库膨胀。
主键使用自增ID
(1)InnoDB要求每张表都要定义主键,并建议主键采用自增ID(AUTO_INCREMENT)的形式。自增ID保证了主键的唯一性,避免了重复插入数据的情况;由于自增ID在插入数据时会按照顺序递增,插入新数据时会直接在表的末尾添加,不会造成数据的移动和调整(减少了页分裂和页合并),能够提高插入效率
- 页分裂现象:页分裂指当一个表中需要插入新的行时,如果该表已经没有空闲的页可用于存储新行,则数据库系统会自动创建一个新的页,这个过程就是页分裂
- 页合并现象:当一个表中已有的行被删除时,如果该页中已有的记录行数量小于页容量的一半,则数据库系统会将该页与邻近的页合并成一个新的页,这个过程就是页合并
(2)如果没有定义主键,那么InnoDB内部会生成一个非单调递增的隐藏主键,可能会导致性能下降
(3)主键一定是聚簇索引,聚簇索引下的数据记录是根据ID排序存储,使用自增ID查询时可以更快地定位数据。
分区表(partition)
分区表概括
分区表含义
通俗地讲,表分区是将一大表,根据条件分割成若干个小表
分表与分区的区别
分表:指的是通过一定规则,将一张表分解成多张不同的表。
分区:从逻辑上来讲只有一张表(虽然在物理层面上是有多个表文件)。
判断是否支持分区
1 | # 方式一:如果输出 have_partitioning YES 则表示支持分区。 |
Range partition(范围分区)
RANGE 分区,基于一个给定连续区间范围,把数据分配到不同的分区
1 | create table goods ( |
List partition(列表分区)
LIST 分区,类似 RANGE 分区,区别在 LIST 分区是基于枚举出的值列表分区,RANGE 是局域给定的连续区间范围分区。
1 | # 如果试图插入的列值不包含分区值列表中时,那么 insert 操作会失败并报错,要重点注意的是,list 分区不存在类似 values less than maxvalue 这样包含其他值在内的定义方式,将要匹配的任何值都必须在值列表中找得到。 |
Hash partition(哈希分区)
HASH 分区,基于给定的分区个数,把数据分配到不同的分区
1 | create table student_hash( |
Key partition(键值分区)
KEY 分区,按照某个字段取余
1 | create table post ( |










